-
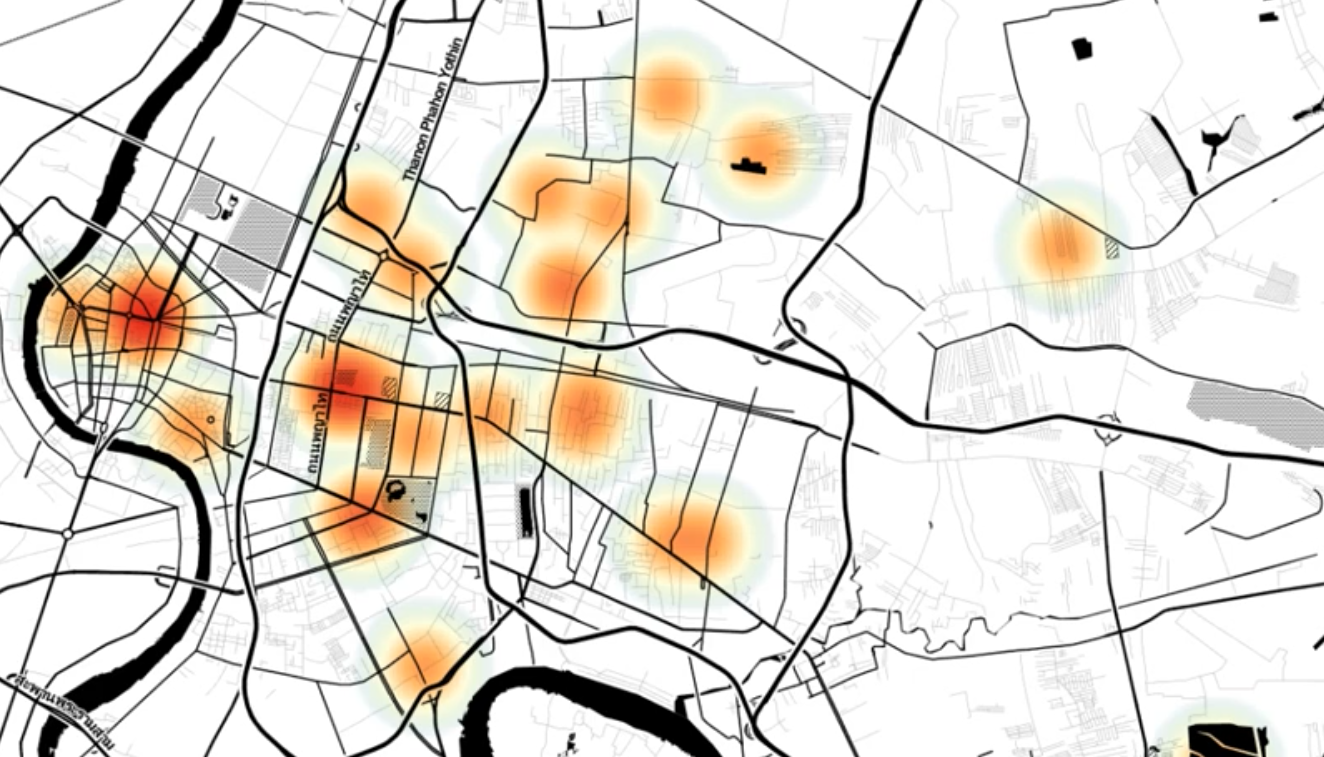
The Spatiality of #BangkokShutdown
Protests in the Thai capital follow spatial patterns (surprise! surprise!)
-
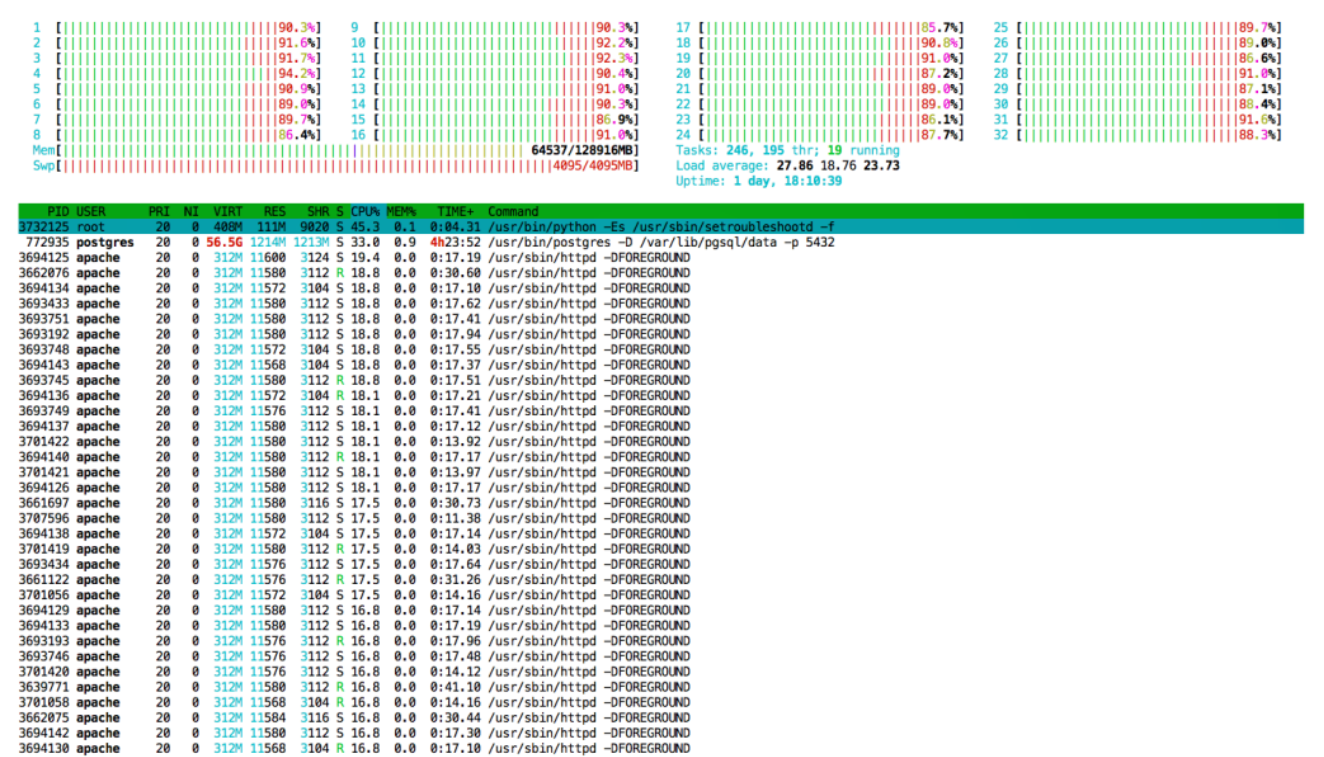
Massive Reverse Geocoding
Finding placenames and adresses for 540 million tweets with coordinates.
-
Auf die Größe kommt es an
Ein Poster am Deutschen Geographentag in Passau erklärt mein Dissertationsvorhaben …
-
Frankenstein, PhD: pseudo-individual populations
Disaggregating demographic, socio-economic and geographic data
-
ECTQG13: one by one
pseudo-individual populations for agent-based simulation models