So my colleagues Izabela and Bartosz collected some 540 million georeferenced tweets for one of their research projects. For the research question it did not suffice to have individual pairs of coordinates. Rather, a placename was necessary – at least a city name, better the name of a neighbourhood or even street.
Bartosz quickly discovered Nominatim, a (reverse) geo-coding engine built upon OpenStreetMap data. He promptly ran into its usage limitations.
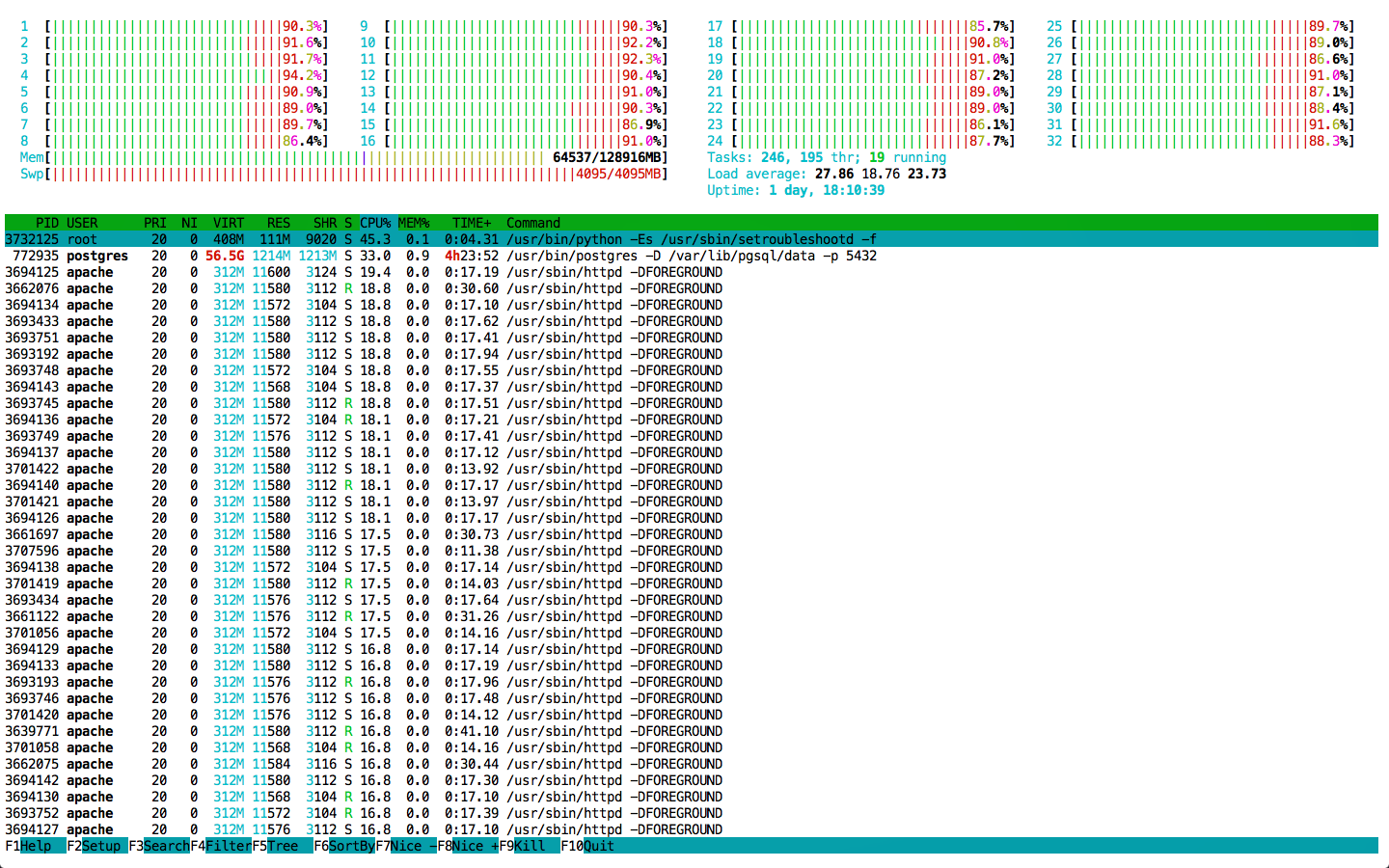
Fortunately, Nominatim is open source software, and the installation procedure is well-documented. Fortunately, we have a high-end workstation sitting in the corner of our office. Fortunately, they had me setting the whole thing up.
First, following the stringent instructions from the Nominatim wiki page, I read in the 30GiB OSM Planet file. This took some 5 days despite the database running on a SuperTalent PCIe SSD (which promises an astonishing 1000MiB/s throughput, both reading and writing). Having two Xeons and 128 GiB of RAM definitely didn’t hurt either.
Initially, the idea was to discard the HTTP API from the Nominatim source, and directly call its core. As it turned out, Nominatim is doing substantial calculation in the PHP frontend code. Time was too short to port this to a locally callable version, so I also set up a webserver, and hooked it up with the API code.
In the meantime, Bartosz had prepared a huge CSV file with three columns, representing the latitude, longitude, and an ID for each of the tweets in question. It was (and is) 542400310 rows long, which accounts for an 18GiB file size.
I devised a Python script employing the multiprocessing module. One sub-process reads in the CSV file line by line, and puts them into a multiprocessing.Queue which in turn serves input to cpu_count + 1 worker processes. These explode the individual lines into columns, query the local (though configurable) Nominatim API interface, and reformat the results into a write-ready CSV output line. Via another Queue these lines are fed into one another sub-process which ultimately writes them to a new file. Finally, I added progress reporting, and a stop-resume routine, as initial estimates tell us the processing will take yet another fortnight.
You can find the source code (which I release in a GPLv2 license) in my bitbucket at https://bitbucket.org/christophfink/nominatim_reversely_geocode_tweets.